Что такое big data: собрали всё самое важное о больших данных
Содержание:
- Каким компаниям нужны аналитики данных?
- Как стать аналитиком данных и где этому учат
- Как готовиться к собеседованиям
- Решения на основе Big data: «Сбербанк», «Билайн» и другие компании
- История вопроса и определение термина
- Кто такой Big data engineer
- Что должен знать Data Engineer
- Что такое «большие данные»
- Большие данные в маркетинге и бизнесе
- Перспективы Big Data в армии
- Обучение профессии аналитик big data
Каким компаниям нужны аналитики данных?
Большие данные — ключевой ресурс для бизнеса: их используют в IT, ритейле, финансах, здравоохранении, игровой индустрии, киберспорте, телекоме, маркетинге. Самые крутые и современные компании называют себя Data-Driven. Они принимают стратегические решения на основе данных.
«На самом деле аналитик данных нужен в любой компании, где есть данные, — уверен Артем Боровой. — Условной сети ларьков с шаурмой он тоже по-хорошему нужен, чтобы анализировать потоки, понимать, где лучше открыть новую точку, выстраивать логистику».
Вот три ситуации, в которых бизнесу может пригодиться специалист по анализу больших данных:
«Плохие» долги. В банке хотят свести к минимуму количество клиентов, которые не возвращают кредиты. Аналитик изучает, какие характеристики клиента указывают на то, будет ли он вовремя вносить платежи. На этом основании клиенту будет одобрен или не одобрен кредит.
Проверка эффективности дизайн-решения. Создатели приложения для знакомств хотят понять, как пользователи реагируют на цвет кнопки. Аналитику данных предстоит протестировать два прототипа: часть пользователей видит вариант с синей кнопкой, другая часть — с красной. В итоге он помогает дизайнеру интерфейса решить, какого цвета кнопка лучше сработает.
Еще благодаря качественному анализу данных можно:
- выявлять настоящие и будущие потребности клиентов;
- прогнозировать спрос на товар или услугу;
- оценивать вероятность ошибки при разных действиях;
- контролировать работу и износ оборудования;
- управлять логистикой;
- следить за эффективностью сотрудников.
Всё это помогает компании узнать о себе больше, увеличить прибыль и сократить издержки.
Как стать аналитиком данных и где этому учат
67% специалистов по аналитике пришли в Data Science из других сфер. В основном это разработчики и маркетологи, но есть и неожиданные профессиональные бэкграунды: геммологи, звукорежиссеры и даже ядерные физики.
Чаще всего изучать аналитику начинают с профессиональной литературы, тематических статей, авторитетных блогов и профильных каналов в мессенджерах. В открытом доступе много теоретической информации, где можно собрать базовый пул теории и практики. И все же для первых самостоятельных шагов нужна система. Проще и быстрее погрузиться в практическую аналитику на образовательных курсах.
Роман Крапивинруководитель проектов, компания ООО «ИНТЭК»:
«В 2020 я задумался о смене профессии, поскольку пандемия коронавируса серьезно ударила по строительному бизнесу, где я работал руководителем проектов последние три года. Долго выбирал онлайн-курсы, хотел прокачать свои скилы в проектном управлении и пошел на курс Project Manager.
Поэтому я начал изучать Power BI, на котором научился визуализировать данные и получил первые знания для дальнейшей работы с аналитическими данными. Но тогда я понял, что для меня мало базовых основ аналитики. Поэтому для себя я открыл профессию Аналитик BI. И в настоящее время изучаю программу визуализации данных Tableau, программу для работы с базами данных SQL, прошел курс по аналитике больших данных (Big Data). К сожалению, на настоящем месте работы я не могу в полной мере применять аналитические знания и программы, которые я освоил. Поэтому задумался о смене профессии: хотел бы попробовать себя в финансовом секторе или крупном ритейле, чтобы погрузиться в мир аналитики».
Иван Натаровконсультант отдела развития предпринимательства Министерства экономического развития Приморского края:
«Будучи студентом магистратуры, проводил исследование инновационной экосистемы Приморского края, тогда познакомился с нейросетями и Data Science. Суть исследования заключалась в разработке алгоритма, основанного на нейросетях и теории нечеткого множества и нечеткой логики, который позволял бы давать объективную оценку инновационного развития региона. У нас это получилось, даже научную статью написали.
Параллельно я изучал Data Science и посетил форум «Открытые инновации» в 2019 году. Послушав экспертов, я понял, что влюбился в эту сферу.
Я люблю узнавать истории из данных, поэтому и выбрал направление аналитики данных.
Я все еще учусь, но почти за год прокачался в этом направлении довольно неплохо. Из инструментов, что я изучил, любимыми стали Python и Power BI, они смогли автоматизировать многие процессы в работе, активно чекаю их. Python больше использую для написания парсеров XML и HTML, Power BI — для предобработки данных и визуализации».
Как готовиться к собеседованиям
Не нужно углубляться только в один предмет. На собеседованиях задают вопросы по статистике, по машинному обучению, программированию. Могут спросить про структуры больших данных, алгоритмы, применение, технологии, про кейсы из реальной жизни: упали сервера, случилась авария — как устранять? Могут быть вопросы по предметной сфере — то, что ближе к бизнесу
И если человек слишком углубился в одну математику, и на собеседовании не сделал простое задание по программированию, то шансы на трудоустройство снижаются. Лучше иметь средний уровень по каждому направлению, чем показать себя хорошо в одном, а в другом провалиться полностью.
Есть список вопросов, которые задают на 80 процентах собеседований. Если это машинное обучение — обязательно спросят про градиентный спуск. Если статистика — нужно будет рассказать про корреляцию и проверку гипотез. По программированию скорее всего дадут небольшую задачу средней сложности. А на задачах можно легко набить руку — просто побольше их решать.
Решения на основе Big data: «Сбербанк», «Билайн» и другие компании
У «Билайна» есть огромное количество данных об абонентах, которые они используют не только для работы с ними, но и для создания аналитических продуктов, вроде внешнего консалтинга или IPTV-аналитики. «Билайн» сегментировали базу и защитили клиентов от денежных махинаций и вирусов, использовав для хранения HDFS и Apache Spark, а для обработки данных — Rapidminer и Python.
Или вспомним «Сбербанк» с их старым кейсом под названием АС САФИ. Это система, которая анализирует фотографии для идентификации клиентов банка и предотвращает мошенничество. Система была внедрена ещё в 2014 году, в основе системы — сравнение фотографий из базы, которые попадают туда с веб-камер на стойках благодаря компьютерному зрению. Основа системы — биометрическая платформа. Благодаря этому, случаи мошенничества уменьшились в 10 раз.
История вопроса и определение термина
При этом уже сейчас термин не использует только ленивый. Особенно часто не по делу термин используют маркетологи. Так что же такое Big Data на самом деле? Раз уж я решил системно изложить и осветить вопрос – необходимо определиться с понятием.
В своей практике я встречался с разными определениями:
· Big Data – это когда данных больше, чем 100Гб (500Гб, 1ТБ, кому что нравится)
· Big Data – это такие данные, которые невозможно обрабатывать в Excel
· Big Data – это такие данные, которые невозможно обработать на одном компьютере
И даже такие:
· Вig Data – это вообще любые данные.
· Big Data не существует, ее придумали маркетологи.
Таким образом под Big Data я буду понимать не какой-то конкретный объём данных и даже не сами данные, а методы их обработки, которые позволяют распредёлено обрабатывать информацию. Эти методы можно применить как к огромным массивам данных (таким как содержание всех страниц в интернете), так и к маленьким (таким как содержимое этой статьи).
Приведу несколько примеров того, что может быть источником данных, для которых необходимы методы работы с большими данными:
· Логи поведения пользователей в интернете
· GPS-сигналы от автомобилей для транспортной компании
· Данные, снимаемые с датчиков в большом адронном коллайдере
· Оцифрованные книги в Российской Государственной Библиотеке
· Информация о транзакциях всех клиентов банка
· Информация о всех покупках в крупной ритейл сети и т.д.
Количество источников данных стремительно растёт, а значит технологии их обработки становятся всё более востребованными.
Кто такой Big data engineer
Задачи, которые выполняет инженер больших данных, входят в цикл разработки машинного обучения. Его работа тесно связана с аналитикой данных и data science.
Главная задача Data engineer — построить систему хранения данных, очистить и отформатировать их, а также настроить процесс обновления и приёма данных для дальнейшей работы с ними. Помимо этого, инженер данных занимается непосредственным созданием моделей обработки информации и машинного обучения.
Инженер данных востребован в самых разных сферах: e-commerce, финансах, туризме, строительстве — в любом бизнесе, где есть поток разнообразных данных и потребность их анализировать.
С технической стороны, наиболее частыми задачами инженера данных можно считать:
Разработка процессов конвейерной обработки данных. Это одна из основных задач BDE в любом проекте. Именно создание структуры процессов обработки и их реализация в контексте конкретной задачи. Эти процессы позволяют с максимальной эффективностью осуществлять ETL (extract, transform, load) — изъятие данных, их трансформирование и загрузку в другую систему для последующей обработки. В статичных и потоковых данных эти процессы значительно различаются. Для этого чаще всего используются фреймворки Kafka, Apache Spark, Storm, Flink, а также облачные сервисы Google Cloud и Azure.
Хранение данных. Разработка механизма хранения и доступа к данным — еще одна частая задача дата-инженеров. Нужно подобрать наиболее соответствующий тип баз данных — реляционные или нереляционные, а затем настроить сами процессы.
Обработка данных. Процессы структурирования, изменения типа, очищения данных и поиска аномалий во всех этих алгоритмах. Предварительная обработка может быть частью либо системы машинного обучения, либо системы конвейерной обработки данных.
Разработка инфраструктуры данных. Дата-инженер принимает участие в развёртывании и настройке существующих решений, определении необходимых ресурсных мощностей для программ и систем, построении систем сбора метрик и логов.
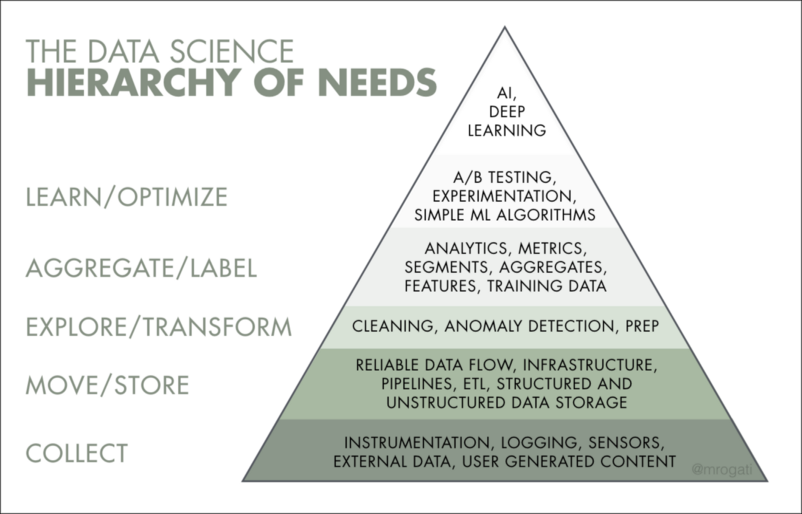
В иерархии работы над данными инженер отвечает за три нижние ступеньки: сбор, обработку и трансформацию данных.
Что должен знать Data Engineer
-
Структуры и алгоритмы данных;
-
Особенности хранения информации в SQL и NoSQL базах данных. Наиболее распространённые: MySQL, PostgreSQL, MongoDB, Oracle, HP Vertica, Amazon Redshift;
-
ETL-системы (BM WebSphere DataStage; Informatica PowerCenter; Oracle Data Integrator; SAP Data Services; SAS Data Integration Server);
-
Облачные сервисы для больших данных Amazon Web Services, Google Cloud Platform, Microsoft Azure;
-
Кластеры больших данных на базе Apache и SQL-движки для анализа данных;
-
Желательно знать языки программирования (Python, Scala, Java).
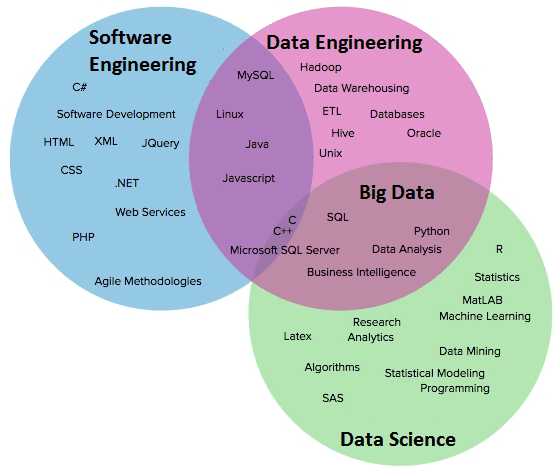
Стек умений и навыков инженера больших данных частично пересекается с дата-сайентистом, но в проектах они, скорее, дополняют друг друга.
Data Engineer сильнее в программировании, чем дата-сайентист. А тот, в свою очередь, сильнее в статистике. Сайентист способен разработать модель-прототип обработки данных, а инженер — качественно воплотить её в реальность и превратить код в продукт, который затем будет решать конкретные задачи.
Инженеру не нужны знания в Business Intelligence, а вот опыт разработки программного обеспечения и администрирования кластеров придётся как раз кстати.
Но, несмотря на то что Data Engineer и Data Scientist должны работать в команде, у них бывают конфликты. Ведь сайентист — это по сути потребитель данных, которые предоставляет инженер. И грамотно налаженная коммуникация между ними — залог успешности проекта в целом.
Плюсы и минусы профессии инженера больших данных
Плюсы:
-
Отрасль в целом и специальность в частности ещё очень молоды. Особенно в России и странах СНГ. Востребованность специалистов по BDE стабильно растёт, появляется всё больше проектов, для которых нужен именно инженер больших данных. На hh.ru, по состоянию на начало апреля, имеется 768 вакансий.
-
Пока что конкуренция на позиции Big Data Engineer в разы ниже, чем у Data Scientist. Для специалистов с опытом в разработке сейчас наиболее благоприятное время, чтобы перейти в специальность. Для изучения профессии с нуля или почти с нуля — тоже вполне хорошо (при должном старании). Тенденция роста рынка в целом будет продолжаться ближайшие несколько лет, и всё это время будет дефицит хороших спецов.
-
Задачи довольно разнообразные — рутина здесь есть, но её довольно немного. В большинстве случаев придётся проявлять изобретательность и применять творческий подход. Любителям экспериментировать тут настоящее раздолье.
Минусы
-
Большое многообразие инструментов и фреймворков. Действительно очень большое — и при подготовке к выполнению задачи приходится серьёзно анализировать преимущества и недостатки в каждом конкретном случае. А для этого нужно довольно глубоко знать возможности каждого из них. Да-да, именно каждого, а не одного или нескольких.
Уже сейчас есть целых шесть платформ, которые распространены в большинстве проектов.
Spark — популярный инструмент с богатой экосистемой и либами, для распределенных вычислений, который может использоваться для пакетных и потоковых приложений. Flink — альтернатива Spark с унифицированным подходом к потоковым/пакетным вычислениям, получила широкую известность в сообществе разработчиков данных. Kafka — сейчас уже полноценная потоковая платформа, способная выполнять аналитику в реальном времени и обрабатывать данные с высокой пропускной способностью. ElasticSearch — распределенный поисковый движок, построенный на основе Apache Lucene. PostgreSQL — популярная бд с открытым исходным кодом. Redshift — аналитическое решение для баз/хранилищ данных от AWS.
-
Без бэкграунда в разработке ворваться в BD Engineering сложно. Подобные кейсы есть, но основу профессии составляют спецы с опытом разработки от 1–2 лет. Да и уверенное владение Python или Scala уже на старте — это мастхэв.
-
Работа такого инженера во многом невидима. Его решения лежат в основе работы других специалистов, но при этом не направлены прямо на потребителя. Их потребитель — это Data Scientist и Data Analyst, из-за чего бывает, что инженера недооценивают. А уж изменить реальное и объективное влияние на конечный продукт и вовсе практически невозможно. Но это вполне компенсируется высокой зарплатой.
Что такое «большие данные»
Вопрос «что называть большими данными» довольно путаный. Даже в публикациях научных журналов описания расходятся. Где-то миллионы наблюдений считаются «обычными» данными, а где-то большими называют уже сотни тысяч, потому что у каждого из наблюдений есть тысяча признаков. Поэтому данные решили условно разбить на три части — малые, средние и большие — по самому простому принципу: объему, который они занимают.
Малые данные — это считанные гигабайты. Средние — все, что около терабайта. Одна из основных характеристик больших данных — вес, который составляет примерно петабайт. Но путаницу это не убрало. Поэтому вот критерий еще проще: все, что не помещается на одном сервере — большие данные.
В малых, средних и больших данных разные принципы работы. Большие данные как правило хранятся в кластере сразу на нескольких серверах. Из-за этого даже простые действия выполняются сложнее.
Например, простая задача — найти среднее значение величины. Если это малые данные, мы просто все складываем и делим на количество. А в больших данных мы не можем собрать сразу всю информацию со всех серверов. Это сложно. Зачастую надо не данные тянуть к себе, а отправлять отдельную программу на каждый сервер. После работы этих программ образуются промежуточные результаты, и среднее значение определяется по ним.

Сергей Ширкин
Большие данные в маркетинге и бизнесе
Все маркетинговые стратегии так или иначе основаны на манипулировании информацией и анализе уже имеющихся данных. Именно поэтому использование больших данных может предугадать и дать возможность скорректировать дальнейшее развитие компании.
К примеру, RTB-аукцион, созданный на основе больших данных, позволяет использовать рекламу более эффективно – определенный товар будет показываться только той группе пользователей, которая заинтересована в его приобретении.
Чем выгодно применение технологий больших данных в маркетинге и бизнесе?
- С их помощью можно гораздо быстрее создавать новые проекты, которые с большой вероятностью станут востребованными среди покупателей.
- Они помогают соотнести требования клиента с существующим или проектируемым сервисом и таким образом подкорректировать их.
- Методы больших данных позволяют оценить степень текущей удовлетворенности всех пользователей и каждого в отдельности.
- Повышение лояльности клиентов обеспечивается за счет методов обработки больших данных.
- Привлечение целевой аудитории в интернете становится более простым благодаря возможности контролировать огромные массивы данных.
Например, один из самых популярных сервисов для прогнозирования вероятной популярности того или иного продукта – Google.trends. Он широко используется маркетологами и аналитиками, позволяя им получить статистику использования данного продукта в прошлом и прогноз на будущий сезон. Это позволяет руководителям компаний более эффективно провести распределение рекламного бюджета, определить, в какую область лучше всего вложить деньги.
Перспективы Big Data в армии
Аналитическая компания из Великобритании GlobalData определили ключевые технологические тенденции, влияющие на внедрение больших данных.
Облачные вычисления
Значение облачных вычислений для обороны растет из-за большого объема данных, производимых военной техникой. Кроме того, облако снижает потребность в поддержке ИТ-систем и инфраструктуры и обеспечивает значительную масштабируемость. Правительство Великобритании уже применяет подход «сначала облако» в отношении защиты используемых в работе устройств.
Периферийные вычисления
Такие вычисления позволяют обрабатывать огромные объемы данных и аналитики. Развитие периферийных вычислений тесно связано с интернетом вещей. Развертывание сотовых технологий 5G станет важным стимулом как для интернета вещей, так и для периферийных вычислений.
Квантовые вычисления
От внедрения квантовых систем выиграют технологии искусственного интеллекта и машинного обучения, поскольку они должны уметь выполнять чрезвычайно сложные вычисления. Системы нового типа позволят легко решать трудоемкие рутинные задачи классификации больших данных и их анализа. Квантовые компьютеры способны выполнять несколько задач параллельно, что ускорит машинное обучение, а, значит, и повысит эффективность обработки Big Data.
ИИ-чипы
Центральные процессоры обеспечивают работу центров обработки данных, но рабочие нагрузки, связанные с ИИ и интернетом вещей, доводят их работу до предела. Однако графические процессоры, которые когда-то использовались в основном для игр, могут обрабатывать множество процессов параллельно. Таким образом, теперь они перемещаются в центры обработки данных.

Индустрия 4.0
Цифровые войны: как искусственный интеллект и большие данные правят миром
Кремниевая фотоника
Это синергия двух групп технологий — электроники и оптики, которая позволяет принципиально изменить систему передачи данных на расстояниях от нескольких миллиметров до тысяч километров. Большинство областей обороны в той или иной степени зависят от оптики и фотоники. Они переходят на оптическую визуализацию, дистанционное зондирование, связь и оптическое оружие. Кремниевая фотоника позволит обеспечить максимально быструю передачу больших данных.
Аналитика в реальном времени
Комбинация потоковых данных и аналитики может принести пользу тем, кто полагается на быстрое принятие решений. Например, ее можно применять для прогнозирования механических отказов в производственной линии на основе данных с умных датчиков.
Когнитивная аналитика
Это модернизированный подход к аналитике и работе с данными, который использует облачные платформы и архитектуру больших данных. В качестве примера можно привести систему IBM Watson. В ее задачи входит разработка и коммерциализация облачных когнитивных сервисов в таких областях как здравоохранение, финансы, путешествия, телекоммуникации и розничная торговля. Суперкомпьютер Watson понимает вопросы, сформулированные на естественном языке, и находит на них ответы с помощью ИИ, а затем анализирует информацию.
Обучение профессии аналитик big data
Для освоения профессии следует начать с профильного базового образования. Получить его можно как за рубежом, так и в России. Для углубленного изучения области big data на рынке представлены очные программы, онлайн курсы и занятия на базе вузов.
Как попасть в профессию:
Какое образование нужно аналитику big data
Человеку с гуманитарным складом ума трудно освоить весь объем необходимых знаний. В идеале кандидату на должность data scientist нужно окончить математическую школу, изучать высшую математику в вузе, а также знать основы теории вероятности, математического анализа и статистики.
Какие программы нужны аналитикам big data
Специалисту нужно понимать, какое программное обеспечение лучше использовать для конкретной задачи. Прогресс не стоит на месте, и новые средства обработки и анализа данных появляются регулярно.
Для анализа часто используют язык программирования R, который обеспечивает статистическую обработку информации и работу с графикой. Также полезно владеть SQL, знать основы Python, Java, Bash и Scala.
Модель MapReduce от Google позволяет проводить распределенные параллельные вычисления на узлах кластера, а затем собирать их в конечный результат.
Одной из основных технологий обработки массива данных считается Hadoop — фреймворк для распределенных программ, работающих на кластерах из огромного количества узлов.
Обучение в вузе
В России получить высшее образование, связанное с анализом больших данных, можно несколькими способами:
- Программа «Прикладной анализ данных» в Высшей школе экономики. Выпускники получают сразу два диплома бакалавра: НИУ ВШЭ и Лондонского университета. Обучение ведется на английском языке и длится 4 года.
- Специализированные программы магистратуры в МГУ, СПбГУ, МФТИ длительностью 2 года. Стоимость обучения в СПбГУ составляет 514,6 тыс. рублей.
- В качестве бэкграунда для data scientist подойдет диплом в сфере математической статистики или информационных технологий. Дальнейшее обучение по специальности можно продолжить на курсах.
Европейские учебные заведения предлагают большой выбор программ по анализу больших данных. Среди них Барселонская технологическая школа. Очный курс обучения продолжительностью в 9 месяцев обойдется слушателям в 17 тыс. евро (1,2 млн рублей).
В Мюнхенском техническом университете можно учиться бесплатно, но отбор студентов проходит жестко: надо предоставить вузовский диплом, мотивационное письмо на английском языке и сертификат TOEFL (не ниже 90 баллов).
Офлайн-курсы для аналитиков big data
На базе вузов существуют программы очного обучения. Курс для слушателей, имеющих базовые знания, длится 24 академических часа и стоит 16 тыс. рублей.
Для руководителей самый дорогой ресурс — это время, поэтому они предпочитают обучаться на интенсивах
Для руководителей, желающих изучить методы и инструменты анализа big data, стоимость трехдневного интенсива начинается от 54 тыс. рублей.
Онлайн-курсы для аналитиков big data
Занятия рассчитаны для учащихся с разным уровнем подготовки. Для начинающих существуют курсы big data с нуля, где за 1,5 месяца и 17 тыс. рублей можно постичь азы профессии.
Углубленный курс может длиться до 1 года и стоить до 150 тыс. рублей. Обучение проводится в формате изучения материала в удобное время, выполнения практических заданий под руководством ментора и сдачи экзамена или дипломной работы.
Некоторые учебные заведения имеют центры развития карьеры и помогают своим выпускникам найти место стажировки или работу.
Бесплатное обучение на аналитика big data
Бесплатные лекции и вебинары в основном дают базовые теоретические знания. Некоторые из них предлагают и практические задания, но не оказывают помощи и консультаций при их выполнении. Существуют и программы с бесплатными учебными материалами, дающие возможность оплатить подписку и получать консультации наставника.
Как правило, организаторы платного обучения предоставляют возможность бесплатно посмотреть вводную лекцию. Это не дает достаточных знаний для работы, но стимулирует слушателей на покупку полного курса.