Кто такой data scientist?
Содержание:
- Робототехника
- Требования к специалисту
- Кто он, Data Scientist?
- Образование в области Data Science: ничего невозможного нет
- Как решать проблему несовпадения ожиданий?
- Подборка хороших курсов
- Какие специалисты работают с данными
- 🥇 №1. Профессия Data Scientist от Skillbox
- Большие данные
- Что такое Data Science?
- Где искать работу?
- Как стать Data scientist: лучшее обучение
- Решаем задачи целиком
- Курсы или халява?
- Что будет на собеседовании
Робототехника
- Роботы (робототехника)
- Робототехника (мировой рынок)
- Обзор: Российский рынок промышленной робототехники 2019
- Карта российского рынка промышленной робототехники
- Промышленные роботы в России
- Каталог систем и проектов Роботы Промышленные
- Топ-30 интеграторов промышленных роботов в России
- Карта российского рынка промышленной робототехники: 4 ключевых сегмента, 170 компаний
- Технологические тенденции развития промышленных роботов
- В промышленности, медицине, боевые (Кибервойны)
- Сервисные роботы
- Каталог систем и проектов Роботы Сервисные
- Collaborative robot, cobot (Коллаборативный робот, кобот)
- IoT — IIoT — Цифровой двойник (Digital Twin)
- Компьютерное зрение (машинное зрение)
- Компьютерное зрение: технологии, рынок, перспективы
- Как роботы заменяют людей
- Секс-роботы
- Роботы-пылесосы
- Искусственный интеллект (ИИ, Artificial intelligence, AI)
- Обзор: Искусственный интеллект 2018
- Искусственный интеллект (рынок России)
- Искусственный интеллект (мировой рынок)
- Искусственный интеллект (рынок Украины)
- В банках, медицине, радиологии, ритейле, ВПК, производственной сфере, образовании, Автопилот, транспорте, логистике, спорте, СМИ и литература, видео (DeepFake, FakeApp), музыке
- Национальная стратегия развития искусственного интеллекта
- Национальная Ассоциация участников рынка робототехники (НАУРР)
- Российская ассоциация искусственного интеллекта
- Национальный центр развития технологий и базовых элементов робототехники
- Международный Центр по робототехнике (IRC) на базе НИТУ МИСиС
Robot Control Meta Language (RCML)
- Машинное обучение, Вредоносное машинное обучение, Разметка данных (data labeling)
- RPA — Роботизированная автоматизация процессов
- Видеоаналитика (машинное зрение)
- Машинный интеллект
- Когнитивный компьютинг
- Наука о данных (Data Science)
- DataLake (Озеро данных)
- BigData
- Нейросети
- Чатботы
- Умные колонки Голосовые помощники
- Безэкипажное судовождение (БЭС)
- Автопилот (беспилотный автомобиль)
- Беспилотные грузовики
- Беспилотные грузовики в России
- В мире и России
- Летающие автомобили
- Электромобили
- Подводные роботы
- Беспилотный летательный аппарат (дрон, БПЛА)
Требования к специалисту
Специалист по данным неразрывно связан с Data Science – наукой о данных. Она находится на пересечении нескольких направлений: математики, статистики, информатики и экономики. Следовательно, специалисты должны понимать и интересоваться каждой из этих наук.
Кроме этого, Data Scientist должен знать:
- Языки программирования для того, чтобы писать на них код. Самые распространенные – это SAS, R, Java, C++ и Python.
- Базы данных MySQL и PostgreSQL.
- Технологии и инструменты для представления отчетов в графическом формате.
- Алгоритмы машинного и глубокого обучения, которые созданы для автоматизации повторяющихся процессов с помощью искусственного интеллекта.
- Как подготовить данные и сделать их перевод в удобный формат.
- Инструменты для работы с Big Data: Hadoop, MapReduce, Apache Hive, Apache Kafka, Apache Spark.
- Как установить закономерности и видеть логические связи в системе полученных сведений.
- Как разработать действенные бизнес-решения.
- Как извлекать нужную информацию из разных источников.
- Английский язык для чтения профессиональной литературы и общения с зарубежными клиентами.
- Как успешно внедрить программу.
- Область деятельности организации, на которую работает.
Помимо того, что специалист по данным должен обладать аналитическим и математическим складом ума, он также должен быть:
- трудолюбивым,
- настойчивым,
- скрупулезным,
- внимательным,
- усидчивым,
- целеустремленным,
- коммуникабельным.
Хочу отметить, что гуманитариям достичь высот в этой профессии будет крайне тяжело. Только при большом желании можно пробовать осваивать данную стезю.
Кто он, Data Scientist?
Вообще-то Data Scientist — профессия, окруженная разными мифами. В глазах одних Data Scientists — это подобие шаманов, способных из «больших данных добывать нефть», причем знаний в области бизнеса от них не требуется. Другие причисляют к этой профессии вообще почти любого программиста: умеешь программировать — умеешь работать с данными.
Мне ближе определение, которое дает специалист по биологической статистике Джеффри Лик из Университета Джонса Хопкинса. Data Scientist — это специалист, владеющий тремя группами навыков:
- IT-грамотность — программирование, придумывание и решение алгоритмических задач, владение софтом;
- Математические и статистические знания;
- Содержательный опыт в какой-то области — понимание бизнес-запросов своей организации или задач своей отрасли науки.
Причем вакансии, подразумевающие эту специализацию, могут называться по-разному. Среди самых популярных названий — аналитик Big Data, математик или математик-программист, менеджер по анализу систем, архитектор Big Data, бизнес-аналитик, BI-аналитик, информационный аналитик, специалист Data Mining, инженер по машинному обучению и многие другие.
Образование в области Data Science: ничего невозможного нет
Сегодня для тех, кто хочет развиваться в сфере анализа больших данных, существует очень много возможностей: различные образовательные курсы, специализации и программы по data science на любой вкус и кошелек, найти подходящий для себя вариант не составит труда. С моими рекомендациями по курсам можно ознакомиться здесь.
Потому как Data Scientist — это человек, который знает математику. Анализ данных, технологии машинного обучения и Big Data – все эти технологии и области знаний используют базовую математику как свою основу.
Читайте по теме: 100 лучших онлайн-курсов от университетов Лиги плюща Многие считают, что математические дисциплины не особо нужны на практике. Но на самом деле это не так.
Приведу пример из нашего опыта. Мы в E-Contenta занимаемся рекомендательными системами. Программист может знать, что для решения задачи рекомендаций видео можно применить матричные разложения, знать библиотеку для любимого языка программирования, где это матричное разложение реализовано, но совершенно не понимать, как это работает и какие есть ограничения. Это приводит к тому, что метод применяется не оптимальным образом или вообще в тех местах, где он не должен применяться, снижая общее качество работы системы.
Хорошее понимание математических основ этих методов и знание их связи с реальными конкретными алгоритмами позволило бы избежать таких проблем.
Кстати, для обучения на различных профессиональных курсах и программах по Big Data зачастую требуется хорошая математическая подготовка.
«А если я не изучал математику или изучал ее так давно, что уже ничего и не помню»? — спросите вы. «Это вовсе не повод ставить на карьере Data Scientist крест и опускать руки», — отвечу я.

Есть немало вводных курсов и инструментов для новичков, позволяющих освежить или подтянуть знания по одной из вышеперечисленных дисциплин. Например, специально для тех, кто хотел бы приобрести знания математики и алгоритмов или освежить их, мы с коллегами разработали специальный курс GoTo Course. Программа включает в себя базовый курс высшей математики, теории вероятностей, алгоритмов и структур данных — это лекции и семинары от опытных практиков
Особое внимание отведено разборам применения теории в практических задачах из реальной жизни. Курс поможет подготовиться к изучению анализа данных и машинного обучения на продвинутом уровне и решению задач на собеседованиях
|
15 сентября в Москве состоится конференция по большим данным Big Data Conference. В программе — бизнес-кейсы, технические решения и научные достижения лучших специалистов в этой области. Приглашаем всех, кто заинтересован в работе с большими данными и хочет их применять в реальном бизнесе. |
Ну а если вы еще не определились, хотите ли заниматься анализом данных и хотели бы для начала оценить свои перспективы в этой профессии, попробуйте почитать специальную литературу, блоги о науке данных или посмотреть лекции. Например, рекомендую почитать хабы по темам Data Mining и Big Data на Habrahabr. Для тех, кто уже хоть немного в теме, со своей стороны порекомендую книгу «Машинное обучение. Наука и искусство построения алгоритмов, которые извлекают знания из данных» Петера Флаха — это одна из немногих книг по машинному обучению на русском языке.
Заниматься Data Science так же трудно, как заниматься наукой в целом. В этой профессии нужно уметь строить гипотезы, ставить вопросы и находить ответы на них. Само слово scientist подталкивает к выводу, что такой специалист должен, прежде всего, быть исследователем, человеком с аналитическим складом ума, способный делать обоснованные выводы из огромных массивов информации в достаточно сжатые строки. Скрупулезный, внимательный, точный — чаще всего он одновременно и программист, и математик.
Как решать проблему несовпадения ожиданий?
Алексей Натекин в своем докладе «Чем отличаются data analyst, data engineer и data scientist» нарисовал картинку с распределением Дирихле, то есть с вероятностью вероятностей.

Предположим, что в Data Science существуют три основные компетенции:
-
Математика. Теоретические знания алгоритмов машинного обучения, и математическая статистика для проверки разных статистических гипотез и обработки результатов, а также любые другие фундаментальные знания, которые будут важны в вашей предметной области.
-
Разработка. Всё, что связано с разработкой, инженерными составляющими проекта, DevOps, SysOps, SRE, и прочее.
-
Предметная область. Навыки коммуникации с коллегами и бизнесом, чтобы понимать, какую проблему они хотят решить, на какие вопросы ответить.
И Data Scientist в этой парадигме — это некоторое наблюдение из нашего распределения Дирихле. Но с помощью этого распределения можно ввести несколько новых должностей, которые будут давать более ясное представление о вашей потенциальной деятельности. Рассмотрим несколько из них.
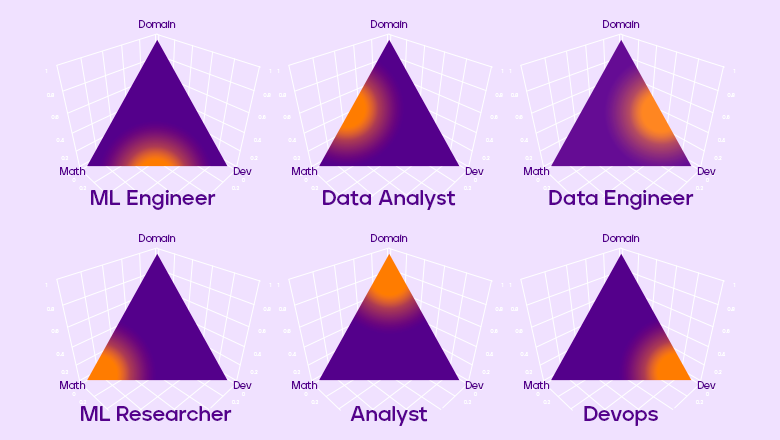
Если вы ищете работу на позицию Machine Learning Engineer, то, скорее всего, будете заниматься введением в эксплуатацию моделей машинного обучения и поддерживать их в актуальном состоянии. Для этого вам потребуются навыки и знания в области алгоритмов машинного обучения, ну и, конечно, разработки.
Если вы аналитик данных, то, вероятно, вы будете заниматься проверкой статистических гипотез, проектировать и проводить эксперименты. Для этого вам требуются фундаментальные знания математической статистики, а также необходимо держать руку на пульсе бизнеса.
Дата-инженер — это человек, который занимается ETL-процессами, архитектурой хранилища, составляет витрины и поддерживает их, организовывает потоковую обработку данных.
Machine Learning Researcher занимается исследовательской работой. Пишет и изучает статьи, придумывает новые математические методы. Таких позиций в России довольно мало, да и встречаются они, как правило, в крупных компаниях, которые могут себе это позволить.
Аналитик — это человек, который отвечает на вопросы бизнеса, и его плотность вероятности приходится на предметную область.
Наконец, DevOps максимально сосредоточен на разработке и развёртывании вашего кода в продакшене.
Подборка хороших курсов
- Практический курс по машинному обучению с менторской поддержкой
- Курс содержит полный обзор современных методов машинного обучения от простых моделей до работы с нейросетями и Big Data от опытного практика области
- Специализация Яндекса и МФТИ на Coursera на русском языке
- Полное введение в data science и машинное обучение на базе Python
- Теорию можно смотреть бесплатно, задания и сертификат — платные
- Интерактивное пошаговое изучение Data Science с фокусом на Python
- Обучение через практику: с самого начала работа с реальными данными и кодом
- 3 направления на выбор: Data Scientist, Data Analyst или Data Engineer
- Интерактивный онлайн-курс по Data Science с фокусом на R
- 66 курсов по машинному обучению, анализу данных и статистике
- Курс построен на решении практических задач
«Специализация Аналитик Данных»
- Специализация включает сквозной курс и тренажёры по инструментам для анализа данных.
- Срок обучения: 6 месяцев
- Онлайн-программа профессиональной переподготовки от Института биоинформатики и Санкт-Петербургского Академического университета РАН, не требующая специальной подготовки
- Срок обучения: 1 год. С лета 2017 — ускоренная программа (полгода)
- Стоимость: 1999 рублей в месяц
Курс по математике для Data Science
Курс содержит много практики, которая не ограничивается решением классических уравнений и абстрактных заданий.
Основы статистики
Бесплатное и ясное введение в математическую статистику для всех
- Легендарный курс основателя Coursera и одного из лучших специалистов по искусственному интеллекту Эндрю Ын (Andrew Ng)
- Этот курс можно считать индустриальным стандартом по введению в машинное обучение
- Добрый человек “перевел” задания на Python (в оригинале нужно все делать на Octave)
- Курс от NVIDIA и SkillFactrory
- Комплексный курс по глубокому обучению на Python для начинающих
- Видеозаписи занятий легендарной Школы анализа данных Яндекса
- Курсы: машинное обучение, алгоритмы и структуры данных, параллельные вычисления, дискретный анализ и теория вероятности и др.
“10 онлайн-курсов по машинному обучению”
Подборка удаленных образовательных программ, составленная проектом “Теплица социальных технологий”
- Любопытное введение в статистику на примере … котиков
- Вы получите знания об основах описательной статистики, дисперсионном и корреляционном анализе
- Фишка курса — наглядность (опять же картинки с котиками)
- Учит извлекать данные из разных файлов, баз данных и API
- Преобразовывать данные для удобного анализа
- Интерпретировать и визуализировать результаты анализа
Курс по Python для анализа данных
Практический курс по Python для аналитиков с менторской поддержкой.
- Курс от Высшей школы экономики
- Онлайн-курс по самому популярному языку программирования для data scientist’ов
Какие специалисты работают с данными
На этапе обработки неструктурированной информации и преобразования ее в базы данных работают ELT-специалисты. К ним относят:
- Data Engineer, задача которого заключается в обеспечении целостности и безопасного хранения информационных баз;
- backend-разработчик — отвечает за поддержание баз данных в работоспособном виде;
- архитектор БД планирует хранение собранных сведений.
При анализе массивов информации требуется извлечь максимум полезных данных. Эти цели реализуют:
- data analyst (аналитик данных) – обрабатывает сведения для решения проблемы с помощью статистических методов, экспериментов, дает прогнозы на перспективу;
- дата сайентист – получает информацию из разных источников для установления закономерностей и развития бизнеса;
- Bl-аналитик – используя готовые решения, занимается их визуализацией;
- Ml-специалист – зная языки программирования и выдвигая гипотезы, разрабатывает алгоритмы анализа.
🥇 №1. Профессия Data Scientist от Skillbox
После прохождения этого курса ты освоишь 2 специальности и получишь 1.5 года реального стажа в Data Science.
Кому подойдёт:
- Новичкам в IT. Чтобы получить базовые навыки программирования, аналитики и математики.
- Программистам. Для улучшения своих знаний и навыков в Python и R.
- Аналитикам. После обучения ты научишься ставить гипотезы, кодить на Python и R, а также повысишь свою квалификацию.
Чему научат:
- Навыкам в аналитике.
- Базовым знаниям по математике для DS.
- Работе с языками Python и R.
- Методам визуализации данных.
- Взаимодействию с базами данных.
- Использованию нейронных сетей и построению рекомендательных систем.
Сколько длится: 18 месяцев.
Цена: 232 500 рублей без скидки, 116 250 рублей со скидкой
Большие данные
Начнём с простого — big data, или «большие данные». Это модный термин, обозначающий огромные массивы данных, которые накапливаются в каких-то больших системах.
Например, человек в Москве совершает 5-6 покупок по карте в день, это около 2 тысяч покупок в год. В стране таких людей, допустим, 80 миллионов. За год это 160 миллиардов покупок. Данные об этих покупках — биг дата.
В банках какой-то страны каждый день совершаются сотни тысяч операций: платежи, переводы, возвраты и так далее. Данные о них хранятся в центральном банке страны — это биг дата.
Ещё биг дата: данные о звонках и смс у мобильного оператора; данные о пассажиропотоке на общественном транспорте; связи между людьми в соцсетях, их лайки и предпочтения; посещённые сайты; данные о покупках в конкретном магазине (которые хранятся в их кассе); данные с шагомеров и тайм-трекеров; скачанные приложения; открытые вами файлы и программы… Короче, любой большой массив данных.
Почему появился такой термин: в конце девяностых компании в США стали понимать, что сидят на довольно больших массивах данных, с которыми непонятно что делать. И чем дальше — тем этих данных больше.
Раньше данные были, условно говоря, по кредитным картам, телефонным счетам и из профильных государственных ведомств; а теперь чем дальше — тем больше всего считается. Супермаркеты научились вести сверхточный учёт склада и продаж. Полиция научилась с высокой точностью следить за машинами на дороге. Появились смартфоны, и вообще вся человеческая жизнь стала оцифровываться.
И вот — данные вроде есть, а что с ними делать? Тут на сцену выходит дата-сайенс — дисциплина о больших данных.
Минутка занудства. Все знают, что правильно говорить «биг дэйта», потому что именно так произносят носители языка. Но в русском языке этот термин прижился с побуквенной транслитерацией — как написано, так и читаем. Поэтому — дата. Кстати, с сайентистами такого не произошло — они звучат так же, как в оригинале.
Что такое Data Science?
Пожалуй, самое лаконичное определение, которое мне удалось найти в интернете:

Я думаю, что если найти пересечение различных определений что же такое Data Science, то им будет лишь одно слово — данные. Всё это говорит о том, что широта применения Data Science огромна. Согласитесь, но ведь в этом нет ничего хорошего ни для кого: ни для вас, ни для бизнеса. Эта широта не дает никакой информации о вашей потенциальной деятельности. Ведь с данными можно делать всё, что угодно. Можно строить сложные отчеты или «шатать» таблички с помощью SQL. Можно предсказывать спрос на такси константой или строить сложные математические модели динамического ценообразования. А еще можно настроить поточную обработку данных для высоконагруженных сервисов, работающих в режиме реального времени.
А вообще, причем здесь слово «наука»? Безусловно, под капотом у Data Science серьезнейший математический аппарат: теория оптимизации, линейная алгебра, математическая статистика и другие области математики. Но настоящим академическим трудом занимаются единицы. Бизнесу нужны не научные труды, а решение проблем. Лишь гиганты могут позволить себе штат сотрудников, которые будут только и делать, что изучать и писать научные труды, придумывать новые и улучшать текущие алгоритмы и методы машинного обучения.
К сожалению, многие эксперты в этой области на разных мероприятиях зачастую связывают Data Science в первую очередь с построением моделей с помощью алгоритмов машинного обучения и довольно редко рассказывают самое важное, по-моему, — откуда возникла потребность в той или иной задаче, как она была сформулирована на «математическом языке», как это всё реализовано в эксплуатации, как провести честный эксперимент, чтобы правильно оценить бизнес-эффект
Где искать работу?
- Много вакансий можно найти на сайтах HH.ru, Яндекс.Работа, Career.habr.com. В ряде случаев компании готовы нанимать специалистов удаленно, то есть с возможностью работать из дома. Как правило, это указывают в вакансиях. Также встречаются предложения по трудоустройству с релокацией (переездом к работодателю).
- Если вы новичок и не имеете опыта работы, то можете посмотреть в сторону стажировок. Они проводятся во многих ИТ-компаниях, после чего успешные кандидаты могут получить предложение о работе.
-
Часто вакансии размещаются на сайтах работодателей. Например, вакансии в Яндексе можно посмотреть здесь.
Как стать Data scientist: лучшее обучение
Следует помнить, что востребованным специалистом не получится стать при самостоятельном изучении всех дисциплин. В любом случае необходимо пройти профессиональные курсы.
Отличный курс для новичков с любым уровнем начальных знаний – «Data scientist» от Skillfaktory. Именно здесь обучение построено таким образом, что на каждом этапе погружения в профессию новичок работает с реальными задачами от партнеров. Каждый полученный кейс входит в портфолио выпускника.
Обучение длится 24 месяца, то есть два семестра по 6 месяцев. За это время новичок достигает уровень Junior с портфолио из 8-и кейсов различных тематик.
Следующие 2 семестра – специализация по выбору. За 12 месяцев студент наполняет свое портфолио еще пятью успешными кейсами. В результате обучения и работы над реальными задачами достигает уровня Middle.

После завершения обучения каждый выпускник обладает знаниями и навыками достигнутого уровня. Может претендовать на соответствующую оплату своего труда.
Особенность обучения на этом курсе в том, что каждый студент в ходе решения задачи может обратиться к куратору. Это помогает оперативно получить ответ на вопрос и поддержку.
За время обучения каждый студент получает 2 года стажа по специальности и профессиональное портфолио уровня Middle. Это значительно экономит время и дает быстрый старт в карьере.
Решаем задачи целиком
Пол Хиемстра, преподаватель и практик Data Science, даёт три совета тем, кто хочет эффективно изучать науку о данных.
Работайте над проектами целиком. У начинающих дата-сайентистов обычно скромная роль, они отвечают за небольшие кусочки проекта. Эту проблему решает pet-проект, который можно делать параллельно с основной работой. Он поможет помнить о масштабе и не работать над разными этапами по отдельности. Конечно, придётся осваивать и точечные навыки (например, какую-нибудь Python-библиотеку), но потом сразу возвращайтесь к целой задаче.
Как сделать pet-проект: найдите датасет из интересующей вас области и проанализируйте его, например, по методологии CRISP-DM. Описывайте каждое своё действие, а главное — соединяйте шаги между собой. Для этого подойдут сервисы типа Google Colab и Jupyter Notebooks. Подробный отчёт о pet-проекте украсит ваше портфолио.
Найдите хорошего наставника. Обсуждать свою работу с опытным дата-сайентистом — хорошая практика. Так вы прокачаете метакогнитивные навыки, которые необходимы для быстрого разбора сложных проблем. В общении с наставником старайтесь фокусироваться на том, как вы решаете проблему — то есть на подходе и идеях, а не на самом решении (коде, модели, библиотеке). Вопросы «а как…» позволяют максимально раскрыть и перенять опыт.

Найдите единомышленников. Объяснение своих решений другим людям, ответы на их вопросы — прекрасный способ лучше понять собственную работу. Помните незадачливого «препода» из анекдота, который на третий раз уже и сам понял, что говорит, а студенты так и не смогли? Так вот — это не просто шутка. А слушая решения других, пытайтесь в первую очередь выяснить, почему ваш собеседник сделал что-либо (например, выбрал конкретную модель).
Курсы или халява?
Выбор между платными курсами и самостоятельным обучением – это индивидуальное решение для каждого. В случае с наукой о данных, есть очень весомые аргументы «за» и «против» каждого варианта. Так, курсы стоят дорого – выше средней цены по современным профессиям, но вместе с тем, они дают возможность учится у практикующих специалистов, которые смогут на понятных примерах объяснить сложные темы.
С другой стороны, много профессиональной информации есть в открытом доступе, и чтобы ее изучить не нужно тратить сотни тысяч рублей. Но остается вопрос – а сможете ли вы разобраться самостоятельно? Чтобы принять взвешенное решение, советуем изучить нашу статью о плюсах и минусах каждого формата обучения: Дистанционное обучение: плюсы и минусы, возможности и преимущества онлайн-обучения
Что будет на собеседовании
Беседа будет строится вокруг:
Вашего опыта, подтвержденного результатом
Важно понимать, как ваш проект повлиял на бизнес, а не как вы повысили auc roc на 2 %.
Ваших знаний о моделях и алгоритмах машинного обучения. Причем вряд ли на собеседовании на позицию, где предстоит заниматься задачами динамического ценообразования, вас будут спрашивать о глубоких нейронных сетях, которые решают задачи сегментации изображений.
Метрик оценки качества моделей (как оффлайн, так и онлайн).
Статистических критериев и всего, что каким-то образом связано с проведением экспериментов.
Программирования, например, на Python (задача для разминки: реверсировать список).
Возможно, алгоритмов и структур данных, если ваша работа как-то связана с высоконагруженными сервисами.
Технологий, с которыми вы работали и/или с которыми вам предстоит работать.
Culture fit и поведенческой составляющей.
Примеры популярных технических вопросов на собеседовании с начинающим специалистом, ответы на которые, увы, могут дать далеко не все:
-
Что такое логистическая регрессия и как она работает?
-
Чем фундаментально отличается градиентный бустинг на деревьях от алгоритма случайного леса?
-
Как проверить статистическую значимость в АБ-эксперименте?
-
Какие вы знаете метрики оценки качества в задачах бинарной классификации?
-
Какие встроенные структуры данных в Python неизменяемы?
На самом собеседовании не стесняйтесь задавать вопросы. Это не экзамен, здесь должен быть диалог. Поинтересуйтесь, какая у вас будет команда, задачи, какие технологии вы будете использовать в работе, какие от вас ожидают результаты, какие глобальные цели у компании.